En el cuarto seminario expusimos en grupos nuestro trabajos de estadística y mi grupo salió el segundo, aunque estábamos muy nerviosas lo expusimos lo mejor posible, ya que este trabajo ha supuesto mucho esfuerzo, peleas, tiempo y sobretodo superación y se merecía una exposición a su nivel, al parecer salió todo bien, por fin respiramos tranquilas después de nuestra última exposición de primero de carrera.
En fin, esta es la última entrada de mi blog, espero que os haya gustado y ayudado a todos.

viernes, 14 de junio de 2013
Tercer seminario
Bueno
el tercero fue el último seminario que tuvimos acerca del programa “Epi Info” y
en el descubrimos, en el estudio que estuvimos tratando en los demás
seminarios, cuál era el alimento que provoco la gastroenteritis en la fiesta y
era la vainilla, llegamos a esa conclusión mediante el manejo de medias, tablas
de frecuencias, test de hipótesis, etc, que nos ayudó a ver las relaciones
entre nuestras variables.
Hipótesis estadísticas. Test de hipótesis.
Este tema se ha convertido en uno de mis favoritos, ya que por fin hay que realizar cálculos y dejarse de tanta teoría, espero que os guste.
Para controlar los errores aleatorios contamos con los tests o contrastes de hipótesis.
Para controlar los errores aleatorios contamos con los tests o contrastes de hipótesis.
Tipos
de análisis estadísticos según el tipo de variables implicadas en el estudio
Predictora/Resultado
|
Dicotómica
|
Continua
|
Dicotómica
|
Test
x2 (chicuadrado)
|
T
de student
|
Continua
|
Regresión
logística
|
Regresión
lineal
|
Chi cuadrado también sirve para cualitativas que no
sean dicotómicas sino policotómicas.
Debemos tener en cuenta los errores de hipótesis: con
una misma muestra podemos aceptar o rechazar la hipótesis nula, todo
depende de un error, al que llamamos alfa, este es la probabilidad de equivocarnos al rechazar la hipótesis
nula, el
error alfa más pequeño al que podemos rechazar la hipótesis nula es el
error y habitualmente
rechazamos la hipótesis nula para un nivel alfa máximo del 5% (p<0’05), es lo
que llamamos significación estadística.
Tipo
de errores en test de hipótesis
Realidad/ resultado del
test
|
Rechazo H0
|
Acepto H0
|
H0 cierta
|
Error
tipo I (error alfa)
|
No
error (1-alfa)
|
H0 falsa
|
No
error (1-beta)
|
Error
tipo II (error beta)
|
Estadística inferencial: muestreo y estimación
Nada más empezar esta entrada debemos dejar claro
que al conjunto de procedimientos que permiten elegir muestras de tal forma que
éstas reflejen las características de la población llamamos técnica de muestreo
y que siempre que trabajamos con muestras debemos asumir un cierto error.
Hablando de errores, definiremos que es un error
estándar: es la medida que trata de captar la variabilidad de los valores del
estimador, mide el grado de variabilidad en los valores del estimador en las
distintas muestras de un determinado tamaño que pudiésemos tomar de una
población. Cuanto más pequeño es el error estándar de un estimador, más nos
podemos fiar del valor de una muestra concreta.
Intervalos de confianza: Son un medio de conocer el
parámetro en una población midiendo el error que tiene que ver con el azar
(error aleatorio), se trata de un par de números tales que, con un nivel de
confianza determinados, podamos asegurar que el valor del parámetro es mayor o
menos que ambos números. Se puede calcular intervalos de confianza para
cualquier parámetro.
Tipos de muestreo:
Muestreo probabilístico (Aleatorio): Es el método
que cosiste en extraer una parte (o muestra) de forma que todas las muestras
posibles del tamaño fijo, tengan la misma posibilidad de ser seleccionadas,
dentro de este existen diferentes tipos:
- Aleatorio
simple: Se caracteriza porque cada unidad tiene la probabilidad equitativa
de ser incluida en la muestra.
- Sistemático:
Similar al aleatorio simple, en donde cada unidad del universo tiene la
misma probabilidad de ser seleccionada.
- Estratificado:
Se caracteriza por la subdivisión de la población en subgrupos o estratos,
debido a que las variables principales que deben someterse a estudio
presentan cierta variabilidad o distribución conocida que puede afectar a
los resultados.
- Conglomerado:
Se usa cuando no se dispone de una lista detallada y enumerada de cada una
de las unidades que conforman el universo y resulta más complejo
elaborarla. En la selección de la muestra en lugar de escoger cada unidad
se toman los subgrupos o conjuntos de unidad “conglomerados”.
Muestreo no probabilístico: No puede considerarse
que la muestra sea representativa de una población, se caracteriza porque el
investigador selecciona la muestra siguiendo algunos criterios identificados
para los fines del estudio que realiza. Hay diferentes tipos:
- Por
conveniencia o Intencional: En el que el investigador decide, según sus
objetivos, los elementos que integrarán la muestra, considerando las
unidades “típicas” de la población que desea conocer.
- Por
cuotas: En el que el investigador selecciona la muestra considerando
algunos fenómenos o variables a estudiar, como: Sexo, raza, religión, etc.
- Accidental:
Consiste en utilizar para el estudio las personas disponibles en un
momento dado, según lo que interesa estudiar. De las tres es la más
deficiente.
jueves, 13 de junio de 2013
Segundo seminario
En el
segundo seminario lo que hicimos fue analizar los datos que introducimos en el
primer seminario.
Para
ello, nuestro profesor nos enseñó algunas herramientas que posee Epi Info para
agrupar categorías, así como ver los datos del estudio. En este caso el estudio
trataba de una población que había asistido a una fiesta y que un gran número
de ellos cogieron gastroenteritis, entonces con los datos ya introducidos de
qué habían ingerido cada una de estas personas así como otros datos relevantes,
pudimos observar qué habían comido estas personas, qué número de ellas se
habían puesto malas y pudimos sacar nuestras propias conjeturas, incluso
representarlo gráficamente mediante el uso de gráficos.

Medidas de tendencia central, posición y dispersión.
Esta entrada va dirigida a las medidas de tendencia central, posición y dispersión, por lo que al ser conceptos clave no puedo explicarlo exactamente con mis palabras por lo que he aclarado los conceptos y colocado gráficas para que se vean más claras estas medidas.
.jpg)

Empezamos definiendo qué es un parámetro o estadístico: es un número que resume
la información recogida en una población o una muestra y existen tres tipos de estadísticos:
- Medidas
de tendencia central
- Medidas
de posición
- Medidas
de dispersión
Medidas
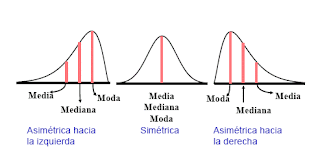
de tendencia central
- Media
aritmética o media: es la suma de todos los valores de la variable
observada entre el total de observación.
- Media
ponderada: es la media de diferentes valores.
- Mediana: es el valor de la
observación tal que un 50% de los datos es menor y otro 50% es mayor.
- Moda: es
el valor que más veces se repite.
Medidas
de posición
- Cuantiles
o n-tiles: sólo tienen en cuenta la posición de los valores en la muestra.
- Percentiles: dividen la muestra ordenada en 100 partes.
- Deciles: dividen la muestra ordenada en 10 partes.
- Cuartiles: dividen la muestra ordenada en 4 partes.
Medidas
de dispersión
- Rango
o recorrido: diferencia entre el mayor y el menos valor de la muestra.
- Desviación
media: media aritmética de las distancias de cada observación con respecto
a la media de la muestra.
- Desviación
típica: cuantifica el error que cometemos si representamos una muestra
únicamente pos su medida.
- Varianza:
expresa la misma información en valores cuadráticos.
- Recorrido
intercuartílico: diferencia entre el tercer y el primer cuartil.
- Coeficiente
de variación: nos sirve para comparar la heterogeneidad de dos series
numéricas con independencia de las unidades de medidas.
Distribuciones
normales:
- En
estadística se llama distribución normal, distribución de Gauss, a una de
las distribuciones de probabilidad de variable continua que con más
frecuencia aparece en fenómenos reales.
- Esta
curva se conoce como campana de Gauss. (ejemplo gráfico)
.jpg)
Asimetría y curtosis:
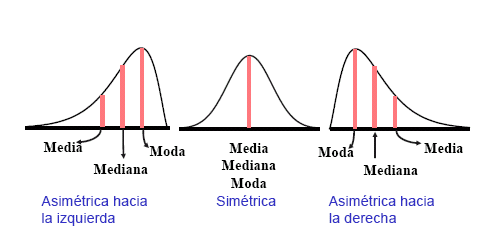
Coeficiente de asimetría de una variable: Grado de
asimetría de la distribución de sus datos en torno a su media.
·
g1=0 (distribución simétrica)
·
g1>0 (distribución asimétrica
positiva, existe mayor concentración de valores a la derecha que a la
izquierda)
·
g1<0 (distribución asimétrica
negativa, existe mayor concentración de valores a la izquierda que a la
derecha)
Curtosis
o apuntamiento:
- Es una
variable sirve para medir el grado de concentración de los valores que
toma en torno a su media
- Los
resultados pueden ser los siguientes:
×
g2=0 (distribución mesocúrtica, es
una distribución normal)
×
g2>0 (distribución leptocúrtica,
larga (hacia arriba))
×
g2<0 (distribución platicúrtica,
más llana (hacia abajo))
Introducción a la bioestadística. Organización de los datos.
En este tema conoceremos conceptos claves a la hora
de desarrollar nuestros métodos y el material necesario para nuestro estudio.
Para empezar hablaremos de la población de estudio
que no es más que la selección de las personas que vamos a incluir y excluir de
nuestro estudio conservando así la validez interna y externa de este, evitando
los sesgos de selección que hayamos tomado en cuenta anteriormente. También
hablaremos del muestreo, el muestreo no es más que el número de individuos que
necesitamos para el estudio ya que es imposible incorporar a toda la
población. Existen diferentes tipos de
muestreo: el muestreo aleatorio simple, el sistemático, el equi-probabilístico,
el estratificado, el multi-etápico, el monstro consecutivo y por último los
voluntarios.
La recogida de datos se puede hacer: de forma
directa, por fuentes documentales, a través de encuestas, entrevistas, etc. En
esta fase tenemos que tener en cuenta los sesgos de clasificación y, si es
posible, hacer un pilotaje previo, es decir, hacer una prueba con pocas
personas antes de hacer el estudio.
A la hora del análisis, mediante el programa “Epi
Info” podemos analizar los datos mediante el uso de: tablas de frecuencia
(tablas que muestran las frecuencias y las categorías de las variables, las
frecuencias son el número de veces que una categoría aparece en nuestra
población de estudio), frecuencia absoluta (número de veces que se repite cada
categoría de la variable de estudio), frecuencia relativa (frecuencia absoluta
dividida por el número total de casos, la suma de estas debe ser 1), frecuencia
acumulada (suma de las frecuencias correspondientes a cada valor) y
representación de datos mediante gráficas (exponen los datos obtenidos en
nuestro estudio de forma gráfica, nos ayuda a aclarar los datos)
Suscribirse a:
Entradas (Atom)